Benchmarks IA
Arena.ai : 100 M$ en 8 mois, ou pourquoi vos évaluations d'IA valent de l'or
Par Yacine Zahidi
Co-fondateur de SprintOS · 1 juillet 2026 · 13 min de lecture
En huit mois, Arena.ai est passée de 0 à 100 millions de dollars de revenu annualisé. Son produit ? De l'évaluation d'IA. Ce chiffre, l'un des plus rapides de l'histoire des logiciels, n'est pas une anecdote de plus dans l'emballement de l'IA. C'est un signal stratégique majeur pour toute entreprise : à l'heure où les modèles se multiplient et se banalisent, la capacité à mesurer lequel fonctionne vraiment, pour quel usage, devient l'un des actifs les plus précieux. Et cette capacité, vous pouvez la construire chez vous.
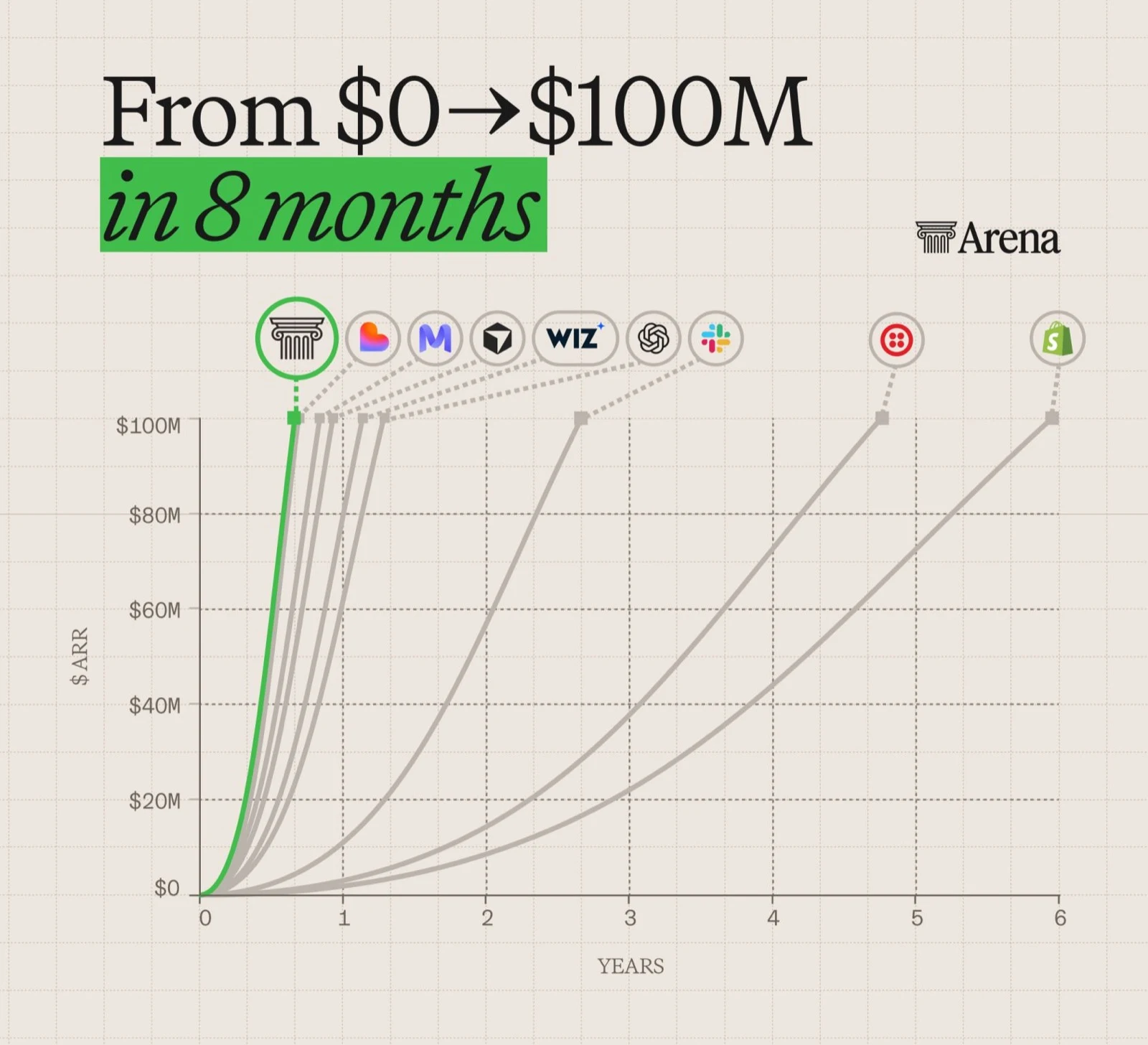
De projet étudiant de Berkeley à 100 M$
Arena.ai n'est pas partie de rien : elle est partie d'un classement. En 2023, des chercheurs de l'université de Berkeley (le groupe LMSYS) lancent Chatbot Arena. L'idée est simple et brillante : plutôt que de noter les modèles sur des questions figées, on met deux réponses anonymes côte à côte et on laisse de vrais utilisateurs voter pour la meilleure. Les identités ne sont révélées qu'après le vote, et un classement statistique (le système Bradley-Terry, cousin du Elo des échecs) agrège des millions de préférences humaines.
Ce tableau de bord est vite devenu la référence du secteur : c'est « l'Arena » que tout le monde regarde pour savoir quel modèle est en tête. En janvier 2026, LMArena abandonne le « LM » pour devenir simplement Arena, signe qu'elle dépasse le seul texte pour évaluer le code, la vision, l'image, les agents. Comme le résume l'entreprise, sa mission est de « mesurer et faire progresser la frontière de l'IA » pour le monde réel.
Le plus frappant, c'est la trajectoire financière :
| Étape | Date | Chiffre clé |
|---|---|---|
| Lancement de Chatbot Arena (Berkeley) | Avril 2023 | Projet de recherche |
| Levée d'amorçage (a16z, UC Investments) | Mai 2025 | 100 M$, valorisation ~600 M$ |
| Lancement du produit payant « AI Evaluations » | Septembre 2025 | Premier revenu |
| Série A (Felicis, UC Investments) | Janvier 2026 | 150 M$, valorisation ~1,7 Md$ |
| Revenu annualisé | Janvier 2026 | ~30 M$ |
| Revenu annualisé | Juin 2026 | ~100 M$ |
Aujourd'hui, la plateforme revendique plus de 700 millions de conversations, plus de 82 millions de votes et plus de 10 millions de visiteurs mensuels dans plus de 150 pays. Un détail compte pour la suite : chaque jour, environ 80 % des requêtes soumises sont inédites. Autrement dit, le signal ne s'use pas, il se renouvelle. Pour une lecture plus générale du sujet, voyez notre guide comprendre les benchmarks IA.
Ce qu'Arena vend vraiment : de l'évaluation
Le classement public d'Arena est gratuit. Ce que les clients paient, lancé en septembre 2025, c'est un produit d'évaluation approfondie destiné aux laboratoires d'IA et aux entreprises : des analyses fines de performance, adossées à des retours humains réels, à grande échelle. Les laboratoires s'en servent pour améliorer leurs modèles ; les entreprises, pour choisir les bons outils.
Une nuance d'honnêteté intellectuelle : le PDG d'Arena, Anastasios Angelopoulos, précise (dans TechCrunch) que ce revenu est facturé à la consommation et « n'est pas récurrent au sens classique du SaaS ». Peu importe, au fond. Le fait marquant reste que l'évaluation de l'IA est devenue, à elle seule, une activité à 100 M$. Un marché existe, et il grossit vite, parce que tout le monde a le même problème : trop de modèles, trop de promesses, et aucune certitude sur celui qui marche vraiment.
Il y a même là un renversement savoureux, qui en dit long sur la valeur de la mesure : Arena est sans doute la seule entreprise au monde que les fournisseurs de LLM paient pour faire tourner et évaluer leurs modèles. D'habitude, c'est l'exact inverse : c'est vous qui payez le fournisseur, au token, pour utiliser son modèle. Ici, ce sont les laboratoires qui rémunèrent celui qui les mesure. Quand la mesure vaut plus cher que le modèle lui-même, l'économie s'inverse.
C'est exactement la logique que nous poussons avec SprintAI, notre agent qui ne se contente pas de générer du code mais qui l'exécute et le teste en conditions réelles : évaluer, ce n'est pas une case à cocher, c'est le cœur de la valeur.
Pourquoi les benchmarks publics ne suffisent plus
Si l'évaluation vaut si cher, c'est que les repères publics ont atteint leurs limites. Trois problèmes, bien documentés :
- La contamination. Dès qu'un benchmark est publié, ses questions finissent tôt ou tard dans les données d'entraînement des modèles suivants. Comme le résume le fonds a16z, un benchmark statique est « contaminé dès sa publication ». Le modèle ne raisonne plus, il a déjà vu la réponse.
- Le sur-apprentissage. Quand une métrique devient un objectif, les modèles apprennent à optimiser la métrique, pas l'utilité réelle. On gagne des points sur le test sans mieux servir l'utilisateur.
- La saturation. Sur beaucoup de classements, les meilleurs modèles se tiennent en quelques points. Le tableau ne discrimine plus : savoir qu'un modèle est premier « en général » ne vous dit rien sur votre cas précis.
Le message est limpide : un bon score public signifie qu'un modèle est bon en moyenne, sur des tâches génériques, souvent en anglais. Il ne dit rien de sa performance sur vos documents, votre métier, vos contraintes réglementaires. Or c'est la seule chose qui compte pour votre entreprise.
Trois façons de mesurer une IA
Encore faut-il s'entendre sur ce que « mesurer » veut dire. Il existe trois grandes manières d'évaluer un modèle, et c'est en les distinguant qu'on comprend la singularité d'Arena. Chacune a sa force et son angle mort.
- La préférence humaine (l'approche d'Arena). Deux réponses anonymes, un vrai utilisateur vote. On mesure la seule chose qui compte au fond : un humain préfère-t-il cette réponse ? C'est ce qui colle le mieux à l'utilité réelle, sur des requêtes fraîches donc difficiles à tricher. Revers : c'est lent, coûteux (il faut du volume de votes), et cela peut récompenser le style (réponses longues, flatteuses) autant que le fond.
- Le LLM comme juge (« LLM-as-a-Judge »). Un modèle puissant note les réponses des autres selon une grille. C'est la méthode qui alimente une bonne partie des classements automatisés, comme Artificial Analysis. Avantage : rapide, peu coûteux, reproductible à grande échelle. Revers : le juge a ses biais (il tend à préférer les réponses longues, son propre style, il est sensible à l'ordre de présentation) et ne peut pas juger mieux que ce qu'il sait lui-même. C'est un proxy du jugement humain, pas le jugement humain.
- Les tâches vérifiables (« verifiable outputs »). On ne demande pas d'avis, on vérifie un résultat objectif : le code passe-t-il les tests ? Le montant extrait est-il le bon ? Le calcul est-il exact ? Avantage : objectif, non manipulable, entièrement automatisable. Revers : ne s'applique qu'aux tâches où une bonne réponse est vérifiable. Cela ne dit rien du ton, de la clarté ou de la pertinence d'une synthèse.
| Méthode | Ce qu'elle mesure bien | Son angle mort |
|---|---|---|
| Préférence humaine (Arena) | Utilité réelle, qualité subjective perçue | Lente, coûteuse, sensible au style |
| LLM juge (Artificial Analysis, etc.) | Vitesse, échelle, coût faible | Biais du juge, plafonné par ses propres limites |
| Tâches vérifiables | Exactitude objective (code, calcul, extraction) | Aveugle au subjectif (ton, clarté, pertinence) |
Des plateformes comme Artificial Analysis sont précieuses pour une vue d'ensemble : elles agrègent des benchmarks standardisés et mesurent aussi la vitesse et le prix. Mais elles restent génériques, sur des tâches qui ne sont pas les vôtres. La bonne nouvelle : ces trois méthodes ne s'opposent pas. Une évaluation privée sérieuse ne choisit pas, elle applique la bonne méthode à chaque tâche : vérifiable là où une vérité terrain existe, LLM juge (calibré) pour le subjectif à grande échelle, vérification humaine sur les cas les plus sensibles. C'est ce mélange, réglé sur votre contexte, qui rend une évaluation digne de confiance.
Le vrai moat : vos évaluations privées
Voici l'insight central, celui qu'Arena monétise à grande échelle et que vous pouvez répliquer à la vôtre : on ne peut pas améliorer ce qu'on ne mesure pas. Et on ne peut pas mesurer sérieusement avec le benchmark de quelqu'un d'autre.
Une évaluation privée (on parle aussi de benchmark sur mesure) renverse la logique. Au lieu de mesurer un modèle « dans l'absolu », elle mesure sa performance sur :
- vos tâches réelles (résumer vos comptes rendus, qualifier vos leads, extraire les clauses de vos contrats) ;
- vos données (votre jargon, vos formats, vos cas limites) ;
- vos critères de réussite (exactitude, ton, conformité, absence d'hallucination sur les points sensibles).
Ce déplacement change tout. a16z le formule sans détour : aucune entreprise ne pariera son activité sur des systèmes « évalués par ceux qui les ont construits ». La confiance vient d'une mesure neutre et propre à votre contexte, pas de la fiche marketing d'un fournisseur. Votre évaluation privée devient le juge de paix : elle tranche entre deux modèles, valide un changement de version, détecte une régression avant vos clients.
| Benchmark public | Évaluation privée | |
|---|---|---|
| Ce qu'il mesure | Performance générale, tâches génériques | Performance sur vos cas d'usage réels |
| Données | Publiques, souvent en anglais | Les vôtres, votre métier, votre langue |
| Risque de triche | Élevé (contamination, sur-apprentissage) | Nul (vos données ne sont pas publiques) |
| Décision qu'il permet | « Ce modèle est bien classé » | « CE modèle marche pour NOUS » |
| Propriété | À tout le monde | À vous seul, un actif |
Comment construire vos évaluations privées
Bonne nouvelle : nul besoin d'une équipe de recherche ni de millions de votes. Un harnais d'évaluation utile se construit par étapes.
- Partir de l'usage réel. On rassemble un jeu d'exemples représentatifs issus de vos vraies tâches, cas limites compris. Quelques dizaines d'exemples bien choisis valent mieux que des milliers de questions génériques.
- Définir les critères de réussite. C'est l'étape décisive. Quand la sortie est vérifiable (un montant, une catégorie, un format), on la teste automatiquement. Quand elle est subjective (un ton, une synthèse), on utilise un modèle comme juge, recoupé par des vérifications humaines sur un échantillon. Bien distinguer ces deux régimes évite les faux positifs.
- Faire tourner tous les candidats. On passe chaque modèle, chaque version, chaque configuration de prompt sur le même jeu, et on compare des scores, pas des impressions.
- Suivre dans le temps et automatiser. On rejoue l'évaluation à chaque changement (nouveau modèle, mise à jour d'un fournisseur, nouveau prompt) pour détecter les régressions avant qu'elles n'atteignent la production, en l'intégrant à votre chaîne de déploiement.
C'est précisément notre métier chez SprintOS, selon une méthode structurée : cadrer vos cas d'usage, construire l'évaluation privée qui les mesure, et l'outiller pour qu'elle tourne en continu. Pour en parler, faites le point avec un expert ou testez vos cas d'usage avec SprintAI.
Pourquoi ces évaluations vaudront de l'or
L'histoire d'Arena n'est pas un cas isolé : c'est le signe avant-coureur d'un déplacement de la valeur. Quatre raisons pour lesquelles vos évaluations privées deviendront un actif stratégique dans les mois et années qui viennent.
1. Les modèles se banalisent, la mesure devient le différenciateur. Avec l'explosion des modèles open-weight performants (voir GLM-5.2 et la montée de l'open source), le modèle brut n'est plus l'avantage compétitif : il y en a des dizaines, comparables et interchangeables. Ce qui vous distingue, c'est votre capacité à choisir le bon pour chaque tâche et à le prouver. Cette capacité, c'est votre évaluation.
2. C'est un actif qui compose. Chaque exemple réel que vous ajoutez rend votre évaluation plus fine, donc vos décisions meilleures, donc vos produits meilleurs. C'est exactement le volant d'inertie d'Arena, à votre échelle : plus vous mesurez, plus le signal devient fiable. Un benchmark privé n'est pas une dépense ponctuelle, c'est un capital qui s'apprécie.
3. Il sécurise vos arbitrages de coût. On ne bascule vers un modèle moins cher (ou vers du prompt caching agressif) que si l'on peut prouver que la qualité tient. Sans évaluation, toute optimisation de coût est un pari à l'aveugle. Avec, elle devient une décision mesurée.
4. Il est à vous, et à personne d'autre. Un benchmark public est un bien commun. Votre évaluation privée, construite sur vos données et vos critères, est inimitable. C'est précisément ce qui en fait un avantage durable plutôt qu'une commodité.
Questions fréquentes
C'est quoi Arena.ai (anciennement LMArena) ?
Arena.ai est une plateforme d'évaluation des modèles d'IA née en 2023 à l'université de Berkeley sous le nom de Chatbot Arena. Le principe : deux réponses de modèles anonymes sont présentées côte à côte, les utilisateurs votent pour la meilleure, et un classement statistique (Bradley-Terry, proche du Elo aux échecs) en est déduit. En janvier 2026, LMArena a été renommée Arena.
Comment Arena.ai a-t-elle atteint 100 M$ en 8 mois ?
En lançant en septembre 2025 un produit payant d'évaluation (AI Evaluations) destiné aux laboratoires d'IA et aux entreprises. Le classement public reste gratuit ; ce que les clients paient, c'est l'analyse fine des performances des modèles sur des retours humains réels. Le chiffre d'affaires annualisé est passé d'environ 30 M$ en janvier 2026 à 100 M$ en juin 2026.
C'est quoi une évaluation (ou benchmark) privée d'IA ?
C'est un jeu de tests taillé pour votre entreprise : vos tâches réelles, vos données, vos critères de réussite. Au lieu de mesurer si un modèle est bon « en général », une évaluation privée mesure s'il est bon pour VOTRE usage. C'est ce qui permet de choisir le bon modèle, de détecter une régression et de comparer objectivement plusieurs options.
Pourquoi les benchmarks publics ne suffisent-ils plus ?
Parce qu'ils sont saturés et contaminés : leurs questions finissent dans les données d'entraînement, les modèles sur-apprennent les métriques plutôt que l'utilité réelle, et tout le monde se tient en haut du classement. Un bon score public ne dit pas si le modèle fonctionne sur vos documents, votre métier et vos contraintes.
Comment construire ses propres évaluations d'IA ?
En partant de cas d'usage réels : on rassemble un jeu d'exemples représentatifs, on définit des critères de réussite (résultats vérifiables quand c'est possible, jugement par un modèle ou par un humain quand c'est subjectif), puis on fait tourner tous les modèles candidats sur ce jeu et on suit les scores dans le temps. L'ensemble s'intègre ensuite à votre chaîne de déploiement.
Faut-il une grosse équipe pour créer un benchmark privé ?
Non. Un premier harnais d'évaluation utile peut se construire à partir de quelques dizaines d'exemples bien choisis. L'enjeu n'est pas le volume, mais la représentativité et la clarté des critères. C'est un travail de cadrage que nous menons avec les PME et ETI, sans mobiliser une équipe de recherche.
En résumé
Le succès fulgurant d'Arena.ai (ex-LMArena) raconte une bascule : dans un monde où les modèles se comptent par dizaines et se ressemblent de plus en plus, la valeur migre du modèle vers la mesure. Les benchmarks publics, contaminés et saturés, ne vous disent plus ce qui marche pour vous. Vos évaluations privées, elles, sont un juge propre à votre contexte, un actif qui s'apprécie et que personne ne peut copier. C'est, très concrètement, l'un des rares avantages durables qu'une entreprise puisse encore se construire sur l'IA. Et le bon moment pour commencer, c'est maintenant, pendant que la plupart mesurent encore à l'aveugle.
Où en est votre PME sur l'IA ?
Un score de maturité en 5 minutes, gratuit et sans engagement.